
All You Need to Know About DNS
Today’s internet represents a huge, enormous network, literally connecting billions of various computers, servers, phones, and even teapots into a single system. There are also over 1.7 billion websites, of which 75% are inactive (just a parked domain). The remaining 25% is made up of more than 400 million websites, most of which you can open right now simply by entering a corresponding domain name. How is that even possible?!
What Is DNS?
It is quite obvious that there is a server behind each website or service, and that server’s real address is not the domain name, but its own IP address. DNS stands for Domain Name System and acts as a glossary of domain names and corresponding IPs. With just a correct IP address, a browser is able to fetch the website’s content. The role of DNS is crucial here, as before your browser requests the content, it first requests data about where to get the desired information.
In reality, DNS is not just a big server with a list of all domain names. Its internal structure is much more complicated, consisting of multiple core parts and servers of all different types, each deserving of a separate explanation.
DNS Recursive Resolver
Just after you type in a url and press enter, the browser sends a query. This is first received by the DNS recursive resolver (often called DNS recursor for short), which is the first step in the address-resolving process. Such a server is usually operated by a client’s ISP (internet service provider), but any other custom public resolver can also be used. The recursor is responsible for resolving the desired IP address by making multiple requests to root, top-level domain and authoritative name servers.
But before taking a closer look at each of these, let’s first understand when all such requests may be simply skipped if the result was already previously cached.
DNS Caching
Considering the fact that IP addresses corresponding to hostnames are changed very rarely, or never at all, it makes sense to optimize the resolving process by storing the relevant information in the resolver’s local cache.
Each time the recursor receives a request, it first tries to find not-expired data about the corresponding hostname’s IP in the local memory. It then either sends a response immediately or starts querying other servers if data is missing or expired. Queries that are successfully handled in this way are named “non-recursive queries.” It is also worth noting that caching can be done on the browser and even operating system levels, meaning that the process can be done even faster and without any recursor interaction at all.
DNS Root Server
Let’s assume that the resolver receives a request to find an IP address for the “mediatemple.net” website. There is no data in cache, so it starts the quest by making a call to the root name server. A root server is responsible for providing information about the DNS servers for any top-level domain, such as “.net,” “.com,” “.org,” etc. It means that the root server can not answer which IP address corresponds to the mediatemple.net, but it definitely can respond with a list of servers responsible for serving a particular top-level domain (.net in our case).
There are around 750 root servers around the world, available from 13 main IP addresses that are permanent and known to every single recursor. Having the information about the TLD (top-level domain) server, the recursor is able to move to the next step and call it.
Top-Level Domain Name Server
Just like a root server, but on a global level, a top-level domain (TLD) server knows information about which servers are responsible for any domain on a particular top-level domain level. For example, the recursor in our case will ask the .net TLD server for the address of the authoritative server for the mediatemple.net domain.
Authoritative Name Server
This kind of name server is usually the last step in the lookup process. It is called “authoritative” because it always provides only actual, not cached, information regarding the domain for which it is responsible. In our example, an authoritative server will respond to the recursor with the relevant data for the mediatemple.net domain, then the recursor will finally respond to the browser with a single or multiple IP addresses. This address (or addresses) should be used to set up a connection to fetch the website’s content.
But a web server’s address is not the only information that an authoritative server holds! What if you need to know the mail server name connected to the same domain, or you need to get a particular subdomain address?
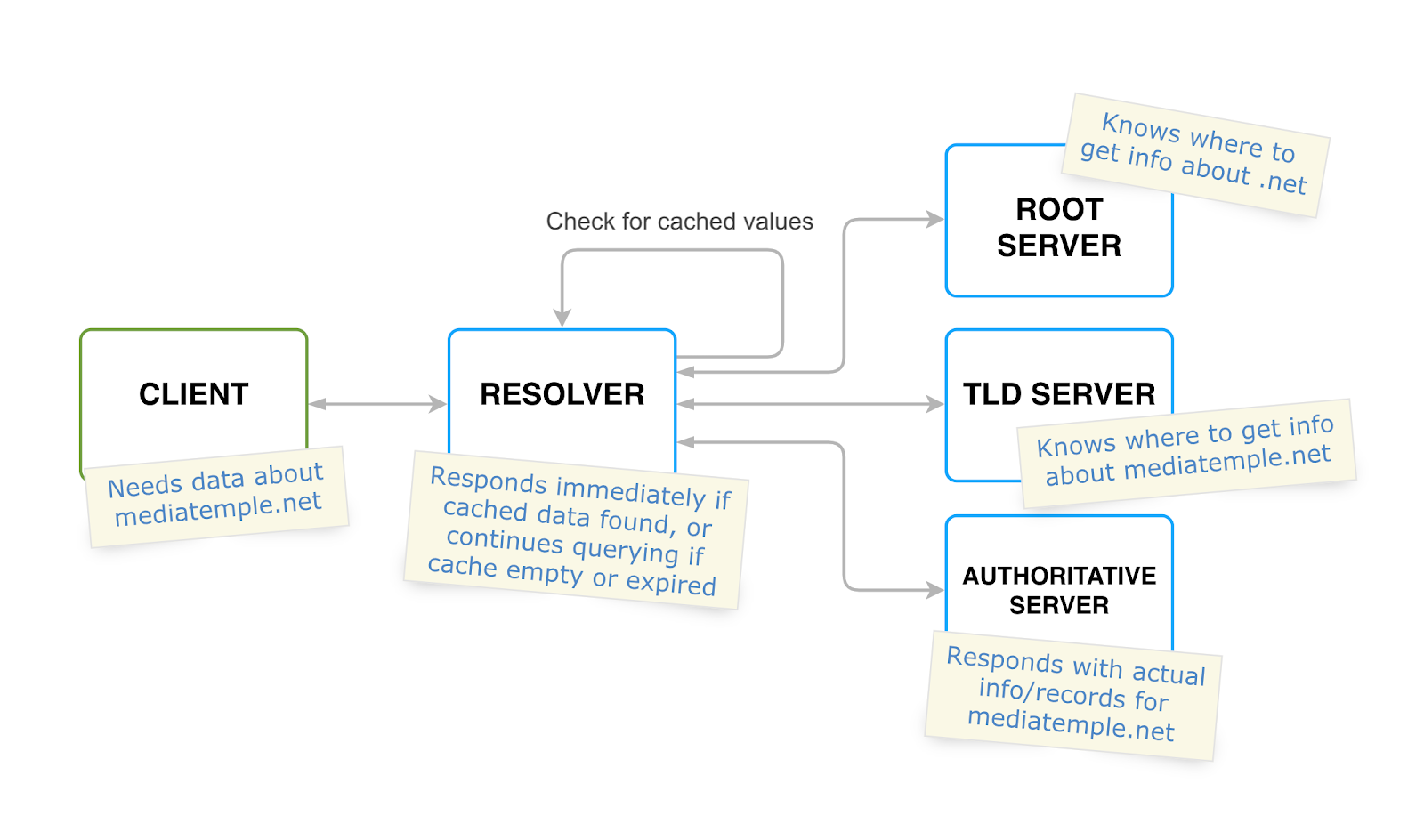
Fig 1: Different DNS servers interaction simplified
DNS Records
DNS records can be considered a list of useful instructions and other data regarding a particular domain. Each item in that list has one of a number of defined types, describing what data it stores.
“A” Record
The most basic and commonly used record type is A (stands for “address”), which maps a domain and/or its subdomains to the corresponding IP addresses. This type was actually required for the browser to open the mediatemple.net page in the example above. There can be multiple A records for a domain and its subdomains.
MX Record
This one stands for “mail exchange” and is used to store the mail server name. It is responsible for proper routing of email messages, pointing to the mail server, and telling mail clients where to send messages. It is also possible to have multiple records of this type; plus you can assign a “priority” value to each MX record, indicating which mail server should be tried first.
Other Records
There are many other record types, including the TXT record for storing custom text data, which is usually used to confirm someone is the owner of a domain or to store custom settings, and the CNAME record for creating aliases, directing requests from one domain to another. You may use the CLI util “host” to get particular record values for any domain.
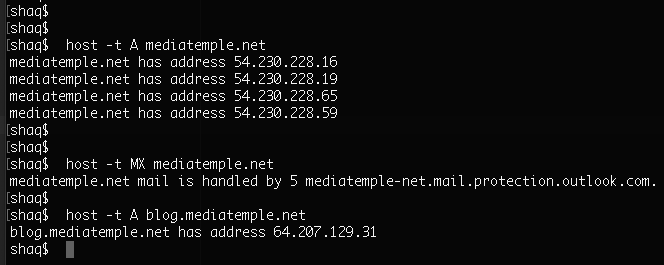
Fig 2: Example of using host util for getting A and MX records
DNS Propagation
As we already mentioned, DNS servers may use cache to speed up and optimize the query process. On the other hand, it means that if the website’s owner makes changes to the DNS configuration, for example, by moving to another hosting provider, those changes are not immediately visible to DNS servers.
First, all requests to the website will be hitting old addresses; but at some point, all servers around the world will gradually refresh the information. This period of time is called DNS Propagation and may take up to three days, depending on configuration, cache clean intervals, and previous TTL values. TTL stands for “time to live” and indicates how long particular record settings should be cached, so the bigger the TTL, the more time that is needed for fresh settings to propagate.
Cloud Providers Go the Extra Mile
Actually, each domain registrar or host allows you to configure DNS settings. But major cloud providers such as AWS or GCP are one step ahead and usually offer extra features. For example, AWS has its own cost-effective and highly available DNS service called Route53, so let’s take it as an example.
AWS Route53 Benefits
Even if a domain is not registered with AWS, it is still possible to move to Route53 and achieve great integration with other AWS services. This point is especially important for those who build their project’s infrastructure on AWS. Using the alias records feature, developers can easily route traffic to specific AWS resources, such as load balancers, API gateways, and S3 buckets.
Also, a cool point about Route53 is its reliability. AWS, being the most mature player on the cloud market, can definitely provide a proper level of security, backed up with solid hardware and stable software.
Route53 provides health-checks functionality as well, helping to monitor a web application’s performance. You can also easily set up a failover policy, which allows for the routing of users to one resource if everything is OK and to another resource if the desired one is not healthy.
Why Is It Important to Understand DNS?
In conclusion, this article shed light only on general principles of how DNS works. But there are more great things about DNS that you should familiarize yourself with, such as DNS security, dynamic DNS, and reverse queries. Setting up DNS attributes is pretty rare during application development and is usually done by DevOps once per project.
However, it would be great if not only the DevOps team, but also each backend and frontend developer, knew about the concepts described. This would allow them to understand how requests reach the destination and what sort of potential issues could occur in their apps, such as those caused by incorrect DNS changes or a long DNS propagation process.




