
Reactive EC2 (ReC2) Management System – Performance for Savings
Welcome to our second entry in Media Temple’s ongoing effort to help you maximize your AWS environment using AWS Lambda. If you missed the first entry, The Reactive Database System – Letting the Cloud Help You, be sure to revisit the Lambda-backed automated RDS monitoring and resizing project (ReDS) it covers in detail.
It’s now time to focus on the Reactive EC2 Management System, aka ReC2. It is a small, friendly Python project that monitors your EC2 Auto Scaling Group to make important adjustments that provide increased reliability and cost savings.
As another addition to the current trend of serverless applications, ReC2 utilizes AWS Lambda to invoke a task at intervals using CloudWatch Events. This means that every five minutes a tiny virtual machine wakes up on Amazon’s Lambda platform and runs a predefined task for a few hundred milliseconds. Then, it shuts itself down.
What’s the problem we’re trying to solve?
AWS has a slew of built-in metric and monitoring systems. Unfortunately, none of them currently allow for a critical scenario to be handled without utilizing Lambda.
That scenario allows you to utilize the cheaper (and often more powerful, dollar for dollar) burstable T-series EC2 instances to the highest threshold of credits usage and then flipping over to C- or M-series instances to adequately handle the increased load. If you are not familiar with how the credits work on T-series instances, don’t worry. Let’s revisit the basic premise, similar to our ReDS blogpost.
Amazon works hard to keep their prices low, and compute resources cost money. The more capacity you wish to have on hand at any time, the more you will be charged for it. Most customers want to have multiple machines online as a fail safe (in case one of them goes offline) to preserve application uptime. However, purchasing two instances with a given amount of compute power essentially means you’re paying double just for insurance. T-series instances help alleviate this situation by giving you an up and running machine with limited compute ability, governed by a credit-based system which depletes and re-fills dependent on usage. When you’re out of credits, the amount of compute that EC2 instance can produce gets throttled down to its baseline performance as shown in the table below.
| Instance type | Base performance (CPU utilization) |
| t2.nano | 5% |
| t2.micro | 10% |
| t2.small | 20% |
| t2.medium | 40% |
| t2.large | 60% |
| t2.xlarge | 90% |
| t2.2xlarge | 135% |
** Note: t2.medium and large instances have more than one vCPU. For t2.2xlarge with 135% base performance, this can mean one core running at 100% with another at just 35%.
Generally speaking, during regular usage your T-series instances have enough CPU credits stored up to use during peak times of the day and refill overnight. It’s like a gas tank: The more CPU power you’re using, the faster you burn your credits (i.e. gas). Once you slow down on the CPU resources – the gas refills again, slowly, until the tank is full. The cycle repeats.
As long as your T-series EC2 servers have some gas in the tank, they’re as good (or better) than the similar, non-credit based EC2 servers with similar characteristics – and cheaper! But therein lies the rub – when and/or if the gas runs out, you can be in real trouble. Unless, of course, you have ReC2 keeping an eye on things.
How do I set it up?
Here’s a high level view:
- Review the project and installation instructions at Github. Here’s the full source code for the project and the README.
- Adjust the variables file to the thresholds you want. If you’re not sure, stick with the defaults, which should work fine for most projects.
- Create CloudWatch alarms to keep an eye on trends and metrics.
- Upload and activate a Lambda task with associated permissions encapsulated in an IAM Role.
- Set up ReC2 to run every 5 minutes and peek at the alarms.
- If any of the alarms are below threshold, ReC2 will temporarily adjust your EC2 servers to run on the more expensive non-credit based instances until the demand recedes.
- The replacement of the Auto Scaling nodes is a zero-downtime event, and happens before you find yourself in an undesirable situation that affects application performance.
As with ReDS, we’ve used pytest to get the major parts of the system tested and covered using bundled test functions. These tests can be modified to your individual project as needed.
A Look at the Variables
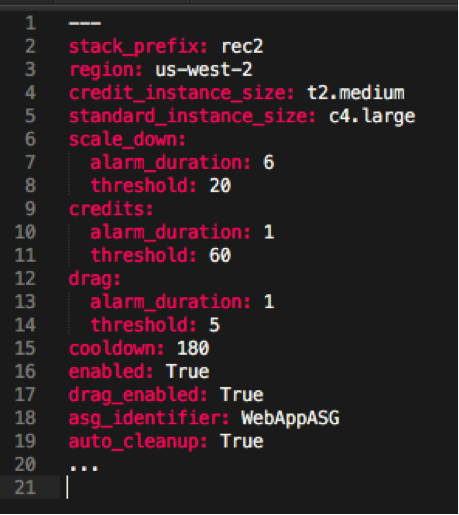
| stack_prefix | The prefix prepended to the associated CloudFormation stacks created during the ReC2 install process. You may have more than one ReC2 system configured allowing you to target multiple Amazon Auto Scaling Groups. Default is ‘rec2’. |
| region | Select the AWS region for the ReC2 CloudFormation stacks. The default is ‘us-west-2’. |
| credit_instance_size | Credit based instance to use. The default is ‘t2.medium’. |
| standard_instance_size | Non-credit based instance to use. The default is ‘c4.large’. |
| scale_down.alarm_duration, scale_down.threshold | Properties to control when the system is allowed to scale back to Credit Based instances based upon CPUUtilization value. The default listed is 6 which equates to 30 minutes (6 periods of 5 minute data) of Auto Scaling Group (ASG) CPUUtilization < 20%, provided the global ‘cooldown’ time has elapsed since the last time instances were moved to non-credit based. |
| credits.alarm_duration, credits.threshold | Properties to control when the system is to change the ASG to non-credit based instances based on average credit balance for the ASG. The default listed is 1 which equates to 5 minutes (6 periods of 5 minute data) of under 60 credits remaining. |
| drag.alarm_duration, drag.threshold | Properties to control when the system is to change the ASG to non-credit based instances based on the lowest single credit balance for an instance in the ASG. The default listed is 1 which equates to 5 minutes under a threshold of five credits remaining. |
| cooldown | The time that must pass (in minutes) after the ASG has moved to non-credit based instances before alarms will be evaluated to see if they meet the criteria to move back to credit based instances. The default is 180 minutes. |
| enabled | Whether the ReC2 system is enabled. The default is “True”. |
| drag_enabled | Whether the ReC2 system will evaluate the “drag” alarm which targets the single lowest machine in the ASG’s credit balance. The default is “True”. |
| asg_identifier | The ASG identifier for your environment. This variable has a default of “WebAppASG”, but must be edited to match your environment or ReC2 will not function properly. |
| auto_cleanup | Whether or not ReC2 will cleanup after itself and remove old launch configurations that it has created for previous adjustments. The default is “True”. |
How does it all work?

Let’s break down the above diagram:
- CloudWatch Events creates an event source to invoke the AWS Lambda project at intervals (5 minutes);
- Lambda spins up and assumes the bundled IAM role. This role is limited to the included IAM policy which only gives it enough access for the project to function properly;
- CloudWatch Alarms are polled and their statuses evaluated;
- Logs of the event are sent to CloudWatch Logs for storage and review;
- And, if warranted, the Lambda function makes the necessary changes to the Launch Configuration tied to the active Auto Scaling Group being monitored.
The goal is simple: Use the credit based T-series instances whenever possible. If ReC2 detects that the ASG (or any single instance, if this option is enabled) is getting into credit trouble, the Launch Configuration is modified to favor the non-credit based instances temporarily to balance out the group until it stabilizes.
These are the major steps. However, there are some additional activities that need to happen in order to make the whole process run smoothly. These include cleaning up old and unused Launch Configurations, adding Tags to the your ASG about previous deployment times for proper cooldown management, and preparing for typical Base64 and UserData situations to ensure the creation of new Launch Configurations.
Savings? Savings.
Let’s say your infrastructure requires two EC2 instances up at all times. According to Amazon best practices, you should have two EC2 instances in at least two availability zones, i.e., four total instances. If your application requires 4GB of RAM on the EC2 server, that leaves you with the non-credit based minimum choices of a current generation instance m4.large (two vCPU, 8GB) or the previous generation m3.large (two vCPU, 7.5GB).
If you are able to use T-series instances (with the added protection of ReC2 to prevent an empty credit balance), this now opens up the opportunity to use a current generation t2.medium (2 vCPU, 4GB) instance as an alternative. For comparison sake, let’s assume you only want to utilize current generation instances for their performance benefits.
If you are not using ReC2 and intend for your app to be both elastic and scalable, you will put your app into potential downtime danger with T-series instances alone. Let’s get the price for a full time setup meeting the above requirements using non-credit based instances at on-demand pricing:
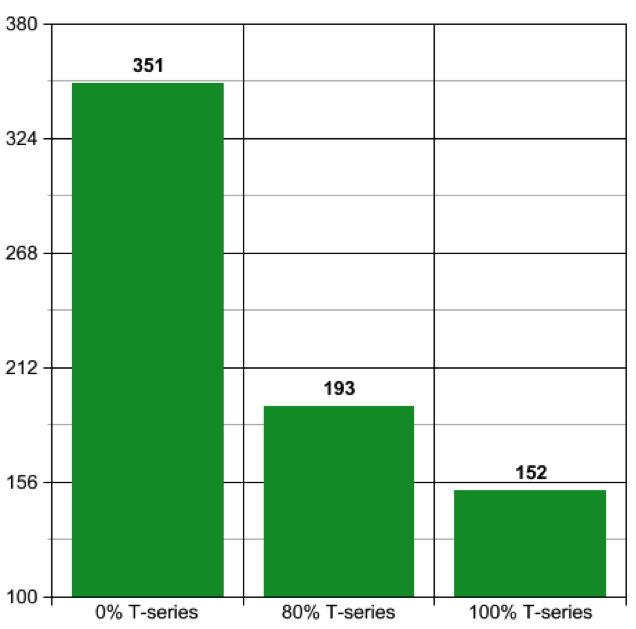
100% Usage of non-credit based instances
4 x m4.large – 100% monthly usage: $351
20% Usage of non-credit based instances due to demand: 45% reduction in cost
4 x m4.large – 20% monthly usage: $71
4 x t2.medium – 80% monthly use: $122
0% Usage of non-credit based instances – Monitored by ReC2: 57% reduction in cost
4 x t2.medium – 100% monthly use: $152
With the above comparison, the non-credit based instances have extra RAM. However, this example is also one of real, actual environments we have configured using ReC2. Discounts in the 30%-50% range are often observed after matching the appropriate T-series instance against comparable M-series and C-series instances for general web-server usage.
Here’s a visual interpretations of the savings (for those of you who love graphs):
$US Dollars per Month
In Conclusion
Given the variety of tools the cloud has available to tailor the exact environment you need for your application, ReC2 has proven to be an efficient cost saver and essential insurance policy.
Here at Media Temple, ReC2 is installed for all new Managed Cloud customers with T-series instances. This is just one of the many ways we’re leveraging cutting-edge technology to keep our customers’ sites and apps online (and at an affordable cost).
If your company or clients can benefit from a consultation with Media Temple’s Enterprise Cloud Services team, feel free to reach out to us today to learn more about our services.
Happy Coding!



