
Beginning the DevOps Journey
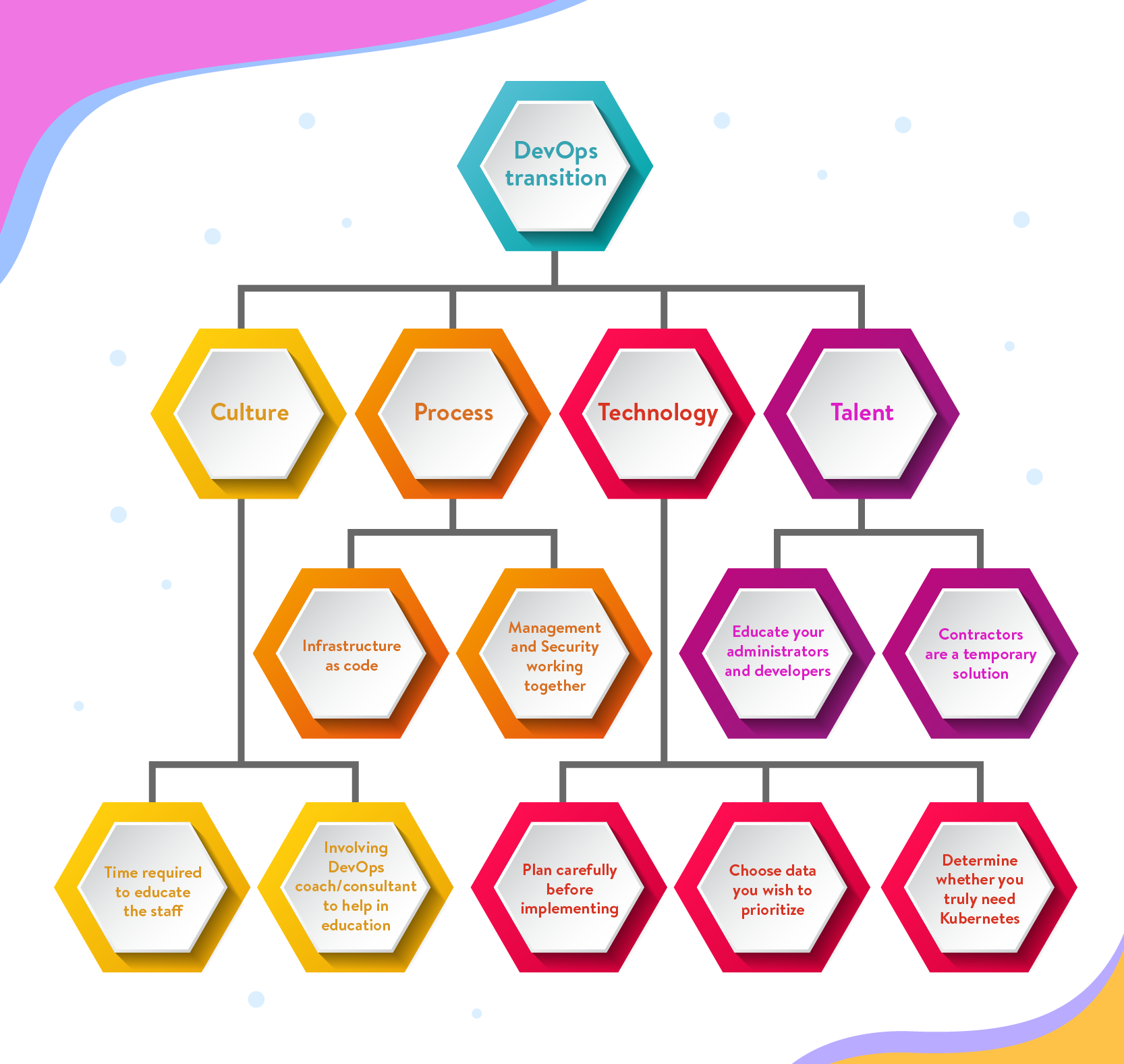
Despite its benefits, adopting DevOps is hard, and many companies struggle to make the transition. It’s easy to fail because there is so much to change. In this article, we’ll focus on four main DevOps components: culture, process, technology, and talent. We’ll explore how to navigate them by introducing common mistakes, explaining why they don’t work, and providing solutions.
Media Temple has adopted the Infrastructure as Code (IaC) DevOps process to better support our customers on Amazon Web Services (AWS). This DevOps process allows us to deliver across a distributed team with a central source of truth for any given infrastructure under our management.
Adopting DevOps can bring the problem-solvers of your company together. It can help you blend ownership and skills across teams. It can enable you to solve problems more efficiently, with higher quality and with more repeatability. DevOps means adjusting your business to meet growing challenges, such as scaling for load, cost, and efficiency, ensuring high availability, and designing for failure. Adopting DevOps means solving those challenges by increased value-driven deployments, reduced complexity, and increased automation.
So, it’s that time. Your company wants to join the craze, to evolve, to be part of the tech revolution. You want to tear down the wall built so long ago between two opposing IT forces: dev and ops. You want change.
Culture
Culture is easy to get wrong because DevOps is a culture — around thinking, problem solving, automation, delivering high quality results, teamwork, and execution. Executives will say they embrace the change from the C-level down, but they often forget to follow their own advice. There can be many reasons for this. Perhaps the CTO hasn’t experienced a transition yet. Or maybe the executives think that DevOps is just a way of combining staff and downsizing—and don’t understand its real value. In any case, it doesn’t matter why there are failures, since they can be avoided.
Common Mistake: “Let’s adopt DevOps but keep doing everything else the same way.”
Why this won’t work: Culture change takes time: Time to train staff, to learn new tools, to learn how to automate-away problems, and to understand how to work together. DevOps should be a transition in itself, just like the migration to a new Platform as a Service (PaaS) or agile development.
The Solution: Projects should be scoped with additional time for staff to learn how to write tests, build in pipelines, automate manual tasks, and experiment with the newly introduced technology.
Common Mistake: “We’ll make the change happen.”
Why this won’t work: It is very difficult to make radical changes without experience in what must change, how to do it, and how to identify problems early.
The Solution: If there aren’t leaders or staff members in place who’ve gone through the DevOps journey, then this is a cautionary tale. Bringing in coaches or consultants who’ve made the transition can go a long way in helping teach good habits and steering those involved in the business—from junior admin to CTO—away from lasting bad practices. Just like companies bring in an agile coach, you can introduce a DevOps coach, who can be just as helpful.
Process
It’s easy to start talking about automation tools like Ansible or Puppet, or discussing Continuous Integration/Continuous Delivery (CI/CD). But let’s start with the basics: changing how developers and operations work together—and with the rest of the business.
Common Mistake: “Let’s create a DevOps team between dev and ops.”
Why this won’t work: Both teams need to blend, and to start sharing responsibilities and workflows. Putting automation experts between both teams will only further isolate them (and alienate them from the transition). Both teams have a lot to give, and the more they work together bringing software from laptop into production, the better.
The Solution: Infrastructure needs to be instituted and treated like software, or infrastructure as code. Ops folks need to learn and understand the power and importance of testing, and developers need to understand that the ops team is part of their planning and application design—not consumers of whatever they want to ship. They should become one delivery team.
Common Mistake: Change management and security can catch up later.
Why this won’t work: This is a huge mistake that should be addressed as the culture shift comes in. The DevOps journey includes everyone responsible for applications and infrastructure health.
The Solution: Change management should start training to become release gates for CI/CD pipelines, or even review automated testing reports (or better, assist in building tests). Security should become involved in introducing security solutions that lend to configuration through automation and APIs. They should also be involved in mitigating security vulnerabilities in the deployment lifecycle, along with the dev and ops teams. EVERYONE IS PART OF THE TRANSITION.
Common Mistake: “That’s the way we’ve always done it here.”
Why this won’t work: Anyone who holds this line is part of the culture drain. If the company is taking steps to enable DevOps, the company is changing—all of it.
The Solution: This kind of mentality (and person) needs to go, no matter how long the antiquated processes have been in place. It’s time to revamp them.
Technology
This is one of the most obvious transitions, but it’s not the most important. There are so many good tools, and so much information available online, that it’s easy to get started. Just Google “devops technology map” and check out the impressive tool lists out there. After evaluating tools, the challenge is picking solutions that work well together and are easy for your teams to start using (effectively).
Common Mistake: Start automating before you know where you’re going (or what you’re doing).
Why this won’t work: It’s easy to bring in a tool like Ansible or start building on Amazon Web Services (AWS) through AWS CloudFormation. After all, you have a staff who wants to get things under automation. You need to bring in deployment pipelines now! If you don’t understand the rules of your infrastructure as code, or how your pipelines will release software, you’ll be stuck with a poorly built framework (tech debt) or have to rebuild it the right way (high cost).
The Solution: Stop. Plan first, before you build and then realize six months into your transition that you need to throw away the design and try again. Review best practices, bring in help, and come up with a design and strategy before you start automating systems and applications. You will want to organize your core configuration/orchestration platform (such as Puppet, Ansible, or Chef), so that automation is consistent and repeatable. You should choose a path of testing, and, at least, a framework for how new code makes it into production, whether traditional deployments or containers. This is where your dev and ops teams can work together to decide how to release software and maintain environments.
Most importantly, this is the time to get your new DevOps engineers (former ops) coding. Test-driven development, coding practices, version-control repositories; all of these things are likely foreign and will take time to learn and adjust to—the sooner, the better.
Common Mistake: “Let’s log everything now and put everything in analytic tools.”
Why this won’t work: Most companies looking to institute DevOps are also either moving into a cloud or planning to move. They decide to not only log everything from every piece of technology, but also to just drop all of it into a tool like Splunk or Sumo Logic, which is a very easy mistake to make. After all, you have all this data and need to get meaningful insights, right? Wrong. You’ll be logging tons of unusable, expensive data.
The Solution: Logging, monitoring, auditing, and alerting — all of these processes are important. And using a tool like Splunk can be very powerful. But before you decide to log and drop information into analytics, you need to determine what is important and what is simply data (noise). As you move to DevOps, start thinking of alerting on only actionable items, and automating away problems that continue to fire alarms. It’s likely not as important to log and maintain all the other data (unless it’s required by regulation to audit), and it will only cost compounded interest, as you log it and stick it in an analyzer.
If you are going to invest in an ELK Stack or Splunk, plan the kind of data you want uploaded. Determine what information you want to get returned, the metrics that are important, and data that would be valuable for the business. Further, identify what is relevant to your engineering, marketing, and sales teams.
Cut the rest.
Common Mistake: “We need to get to Kubernetes, now.”
Why this won’t work: Even modern companies with mature DevOps make this mistake. They determine that they’ve only succeeded when they are managing 10,000 containers in a fully-scaled Kubernetes cluster spanning two clouds. They’ve hit the summit. They are just like Google. This is utterly incorrect. Kubernetes is a powerful tool, but it’s not a silver bullet.
The Solution: Kubernetes is almost necessary when you’re managing a great magnitude of containers. The fact is, most modern tools are powerful and should be used when applicable. Whether you start planning to build microservices, serverless, or container scheduling such as Kubernetes, know why you’re doing it and if it is the right decision.
Talent
Common Mistake: All the systems administrators are now DevOps engineers.
Why this won’t work: This might be the most common mistake. Unless your administrators understand software development, automation best practices, cloud tools, and managing modern application architecture, they probably aren’t ready for the reclassification.
The Solution: It’s time to pay for training, get mentors, and help transform your staff the right way. Do this, and they will be more loyal because you’ve invested in their future (and yours).
Common Mistake: All the developers are now DevOps engineers.
Why this won’t work: Developers have a far more natural segue into DevOps because they understand software, but that doesn’t mean it’s an instant transition. There are good reasons why developers don’t have prod access: many (not all) devs build software to work. Security, scalability, resilience, data management, recoverability; those are “ops” problems, right?
The Solution: Developers will need to learn orchestration, the importance of security best practices, ensuring production is protected, a few layers of the stack below the application, and how all the scaling and resiliency works. They, too, can use mentors, and even training on new application languages such as Go or Elixir, as well as frameworks like microservices.
Common Mistake: “Let’s just get contractors.”
Why this won’t work: If you want your staff to stay for the long haul, then don’t just hire temporary folks to do the work. They may get you transitioned, but they may not be at the level of investment that you would like to see.
The Solution: If you must go this route, integrate contractors with your developers and operations folks and pay for them to cross-train. You’ll want core talent as your DevOps maturity improves, otherwise you’ll always be subject to paying a high fee for maintenance.
Summary
DevOps is a journey, not a destination. It’s not a buzzword, and it’s easily misunderstood—and even easier to make major lasting mistakes when starting the journey. It’s best to invest in people, spend the money necessary to allocate the time to adopt, and bring in experts to help. Avoid the mistakes highlighted in this article and you may find your company reaching that summit yet.
Spoiler: there aren’t 10,000 containers waiting at the top.
Read more about the benefits of the DevOps Infrastructure as Code process, as leveraged by Media Temple.



