Serverless: The New World of Software Development
Serverless is an approach to software development that abstracts the server layer from the application code. The serverless approach is a cornerstone of the modern application, with its distributed components that manage their own server-side logic and infrastructure in response to application events. These components are typically Functions as a Service and third-party microservices, often running on containers.
A recent Allied Market Research report estimates that the global serverless architecture market was worth ~$3.1 billion in 2017, and forecasts that it will grow to ~$22 billion by 2025, at a truly remarkable cumulative annual growth rate of almost 28%. It is not surprising, therefore, that serverless computing tops Gartner’s list of the top 10 infrastructure and operations trends for 2019. The development world is enthusiastically embracing serverless for its frictionless and flexible scalability and high availability. And because serverless apps spin up and terminate instances based on event triggers, they eliminate the phenomenon of idle pre-provisioned resources that drive up costs.
This article is the first of our two-part series about Serverless. In this article, we describe serverless architecture in more detail. In the second article, we’ll discuss the benefits and challenges of serverless, and introduce the tooling that has emerged to facilitate the development, deployment, troubleshooting, and security of serverless apps.
Serverless Architecture: A Primer
Legacy applications manage all client-side and server-side logic and infrastructures within a closed, monolithic architecture. As transactions take place across the various application tiers, the application owner is responsible for providing the resources required to maintain performance and availability SLAs.
Serverless applications, on the other hand, break out the application’s functional components into standalone modules, with transactions choreographed via event-based API calls. The modules are, in effect, black boxes that know how to scale up and down, and to balance loads as necessary to meet performance KPIs. The application owner doesn’t know—and doesn’t care—about how many servers are running at any given time. And, in the case of a serverless application running on the public cloud, the owner won’t even know in which locations those servers are running.
Here’s a simple example of an online pet store from Martin Fowler’s excellent article on serverless architecture.
As a monolithic architecture, it would look something like this:

Figure 1: Online pet store in a monolithic architecture
In a serverless architecture, the application would look something like this:
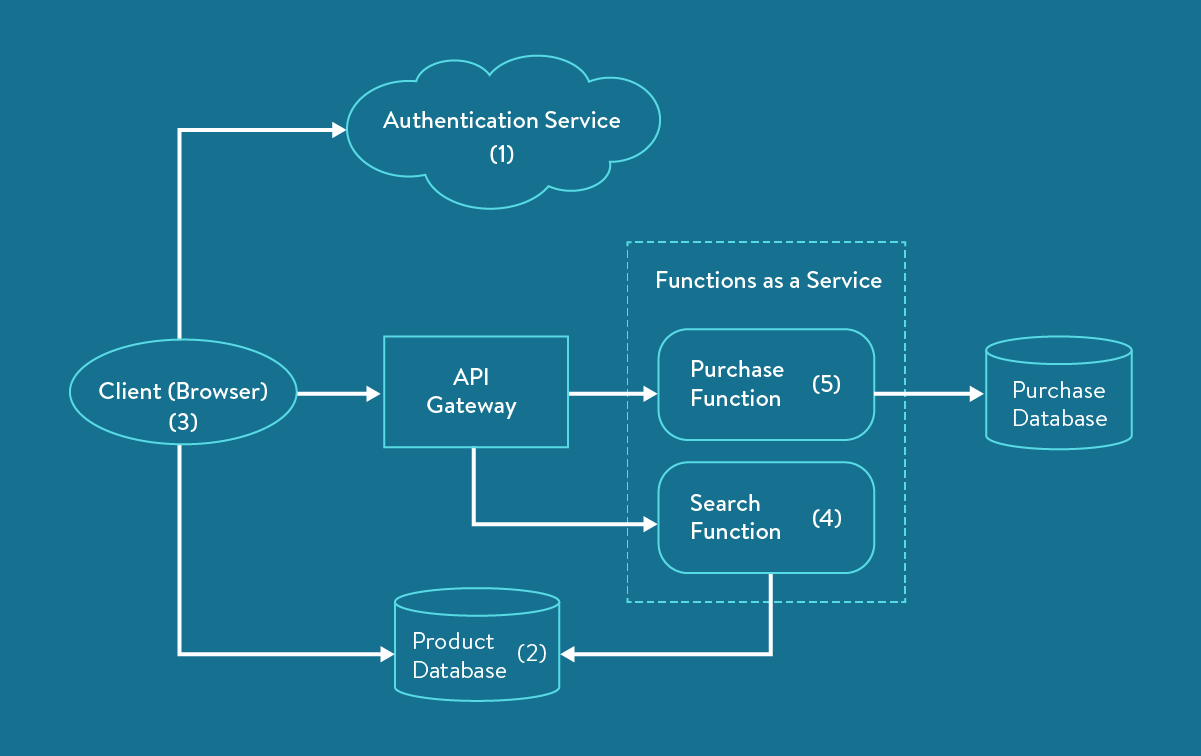
Figure 2: Online pet store in a serverless architecture (highly simplified), based on Serverless Architectures
- The authentication logic is now handled by a third-party service.
- The user now has direct access to a hosted subset of the database for product listings, with appropriately low, read-only privileges. When the same database is approached by server-side logic (4), the privileges can be higher.
- The browser now hosts a single-page application that can implement some system logic, such as tracking user sessions and presenting usable views of the database.
- The Search function can implement both client-side and server-side search requests.
- Keeping the Purchase function server-side enhances security.
The ephemeral and stateless nature of the serverless microservices and functions that make up the modern distributed application is great for agility and scalability. However, these same characteristics also raise architectural challenges that need to be addressed by serverless application developers. Wherever the application flow requires statefulness, for example, the developer must take care to externalize persistence. In addition, the developer must specify adequate runtime memory resources so that performance, availability, and the user experience are not unduly affected by timeouts.
Some typical use cases that lend themselves well to serverless architecture include:
- Auto-scaling websites: Because the serverless backend scales automatically based on runtime demand, fully functional and high performing websites can be launched without upfront infrastructure setup (and testing). The result is much faster time-to-market.
- Incorporating advanced image and video services: A serverless architecture lets you easily integrate with third-party services for value-added features such as dynamic image resizing, device-adapted video transcoding, facial or image recognition, and so on.
- Seamlessly integrating SaaS events into the system logic: Serverless architecture makes it easy to trigger functions based on events from SaaS platforms such as Salesforce, GitHub, AuthO, or Stripe.
Multilingual applications: Serverless architecture makes it possible for components to work together smoothly, even if different components were developed using different development languages and frameworks.
Stay tuned next week for part two of this series. Afterwards, we’ll begin our series on how Serverless fits in with Amazon Web Services.