
The Reactive Database System - Letting the Cloud Help You
No matter what type of site you operate, we all have a similar issue: A database under full load means things will break. Typical LAMP stacks (or similar) suffer from the following challenge: How to keep the database instance class large enough to handle the highest end of traffic at all times, while (hopefully) not overspending. Common applications like WordPress, Drupal, Magento, and other off-the-shelf software can often raise database requirements high enough to get expensive quickly. If you’re lucky, you can get away with clever tuning and caching, and run at a smaller instance size… until you can’t. Unexpected traffic, a viral blog post, or extra searches are common causes for a database to reach its load capacity. If you’ve ever been woken up by system alarms early in the morning, this is a situation you know all too well.
Enter Amazon Auto Scaling Elastic Compute Cloud (Amazon EC2) groups. One of the more well-known features of AWS, extra Amazon EC2 instances can be added when the load gets too high or remove unused instances as needed. Most new AWS users expect this behavior to work the same way on Relational Database Service (Amazon RDS) and allow their DB to grow and shrink along with the work load. Here’s the thing: Searching for “Amazon RDS Autoscaling” generally reveals answers such as this:
Question: Does Amazon Amazon RDS solve the MySQL scaling issue?
Answer: No, Amazon RDS does not solve the scaling issue. (March 2012)
We still stand here today. While there are options to add Read Replica DBs under Amazon RDS (which will automatically receive replication data from the main database and help serve the read requests), there are no simple ways¹ to modify an off-the-shelf piece of software to split the write queries away from the reads². Speaking from experience (and having developed software that performed this action), I can tell you that there are many pitfalls and “gotcha” moments that come along with it. Especially:
-If I read directly after I write, will I get the new data?
-What happens if multiple queries are submitted at once in a single statement separated by semicolons?
-What if I want to write to the session table in the first query, but read in the subsequent queries?
AWS Lambda: Your trustworthy (and inexpensive) friend
One of the most exciting advances to come out of AWS in the past couple of years is AWS Lambda. AWS Lambda is a service that lets you run small, precise code for milliseconds at a time. You only pay for exactly what you use. AWS Lambda also comes with the generous AWS Free Tier that includes 3.2M seconds of compute time at the lowest memory level. This is more than enough time to do quite a bit of tricks in your favor.
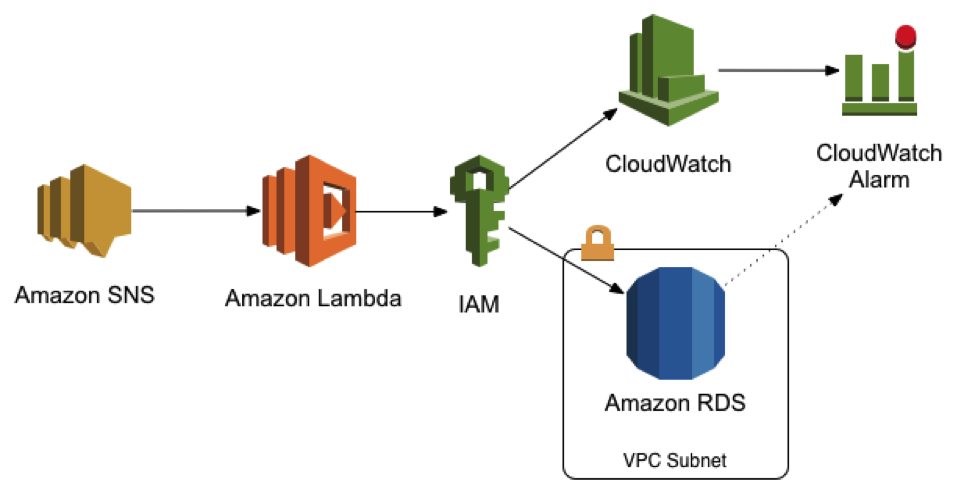
One of those tricks is the Reactive Database System (or “ReDS”). The idea is simple: Use AWS Lambda to monitor your Amazon RDS instance and scale it up when the load is high – and down when it’s low. This is the same general idea as AWS Auto Scaling for Amazon EC2, except that, instead of scaling out with additional instances, we modify the database instance class to a larger size. To accomplish this, the following items are required:
- Multi-AZ Amazon RDS
- AWS Command Line Interface (CLI) user with sufficient permissions
- ReDS
To start, simply download / clone the repository above, modify the variables to fit your needs, and run it. From start to finish, this only takes about five minutes.
Scheduled or Reactive (or both)?
The two main ways to use the system are reactive or scheduled –You can even use both at the same time if you choose.
The reactive method acts like an insurance policy and will most likely save you money. If you believe your website could soon go down from an overloaded database, set the configuration to start out with your current instance size and allow it to move up one or two instance sizes if the CPU shows signs of distress. This is a great situation for using cheaper T2 Amazon RDS instances over the more expensive M class servers. One thing we’ve found at Media Temple is that a T2 medium Amazon RDS is a powerhouse, often handling the workload just as well as the M4 Large (and at half the cost!) It will also likely save you a few hours of sleep on that one morning where a few more users than expected jump onto your website.
ReDS works by monitoring CloudWatch alarms and applying changes as needed. AWS Lambda allows you to set a repeating event to invoke your code as often as every 5 minutes. Each time the ReDS script runs, the variables are read out of a local file. It then connects to AWS and reads data from the API, telling it what alarms are going off and the current status of the instance. Utilizing a well-tested Python script, the system determines the appropriate course of action and invokes the modifications to the Amazon RDS if needed.
The scheduled method involves setting a time for the Amazon RDS server to increase the instance size at a predetermined start time, and returning it back to the original size at a predetermined end time. The normal use case for something like this would be to increase your DB up to a larger instance between standard working hours – maybe Monday-Friday, 9am-5pm and back down afterwards. Allowing your database to scale lower during off hours and the weekends can also save you quite a bit of money. Maybe all that your site requires to perform well on a slow Sunday afternoon is a micro instance Amazon RDS, so why pay for more?
Downtime?
You may be wondering – Will my site be down during the resizing process? The answer is: Yes, but only for a few seconds. In my last several tests against a production Amazon RDS instance, the application was unreachable for 9 to 12 seconds.
This may not be ideal, but it’s not the end of the world. Here’s why:
- If your DB is maxed out under traffic, you’d probably increase the Amazon RDS size anyway.
- If your DB is maxed out, your site is effectively down already. A 9- to 12-second gap won’t hurt.
- If you’re using Amazon CloudFront properly, no one may even notice due to full page caching.
- Your application can be changed to retry DB connections (i.e. ping and retry – see Appendix 1 for an example approach in PHP).
- Resizing can be done on off hours to avoid the impact.
- It doesn’t have to be your production site Amazon RDS instance (i.e. it also works well for reporting instances).
How does it work?
Outside of the logic in the main Python script (and the required Python libraries), the magic is in the applied settings. Here is the default configuration file:
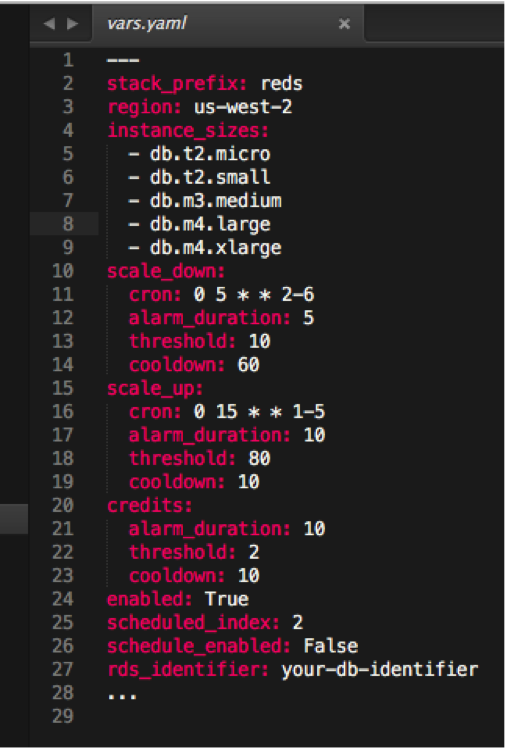
This yaml file contains all of the information for the system. It has three alarm definitions in scale_up, scale_down, & credits. The “credits” alarm is only needed for T series instances. These instance types work with a tracked amount of CPU credits to help keep the cost down. Use more CPU cycles during processing bursts and you burn more credits, use less and you gain them. Think of it as someone filling your gas tank at a slow and steady pace. If you keep your foot on the pedal too long, burning more gas than is being replaced, eventually you’ll run empty. The credit alarm helps prevent you from ending up in that situation where the database runs out of gas.
In addition to the alarms, the cron variables are where the scheduled scaling events are defined. The times are in UTC, so you may need to do a little arithmetic to arrive at the proper values. The numbers above roughly scale up Monday-Friday at 9am and scale down Monday-Friday at 5pm, both Pacific time (currently UTC -7). Cron syntax is a standard in the computer world, so we decided to stick with that. It’s also an easy way to define a repeating pattern.
Table 1: Variable Definitions
| Variable Name | Definition |
| stack_prefix | The prefix prepended to the associated CloudFormation stacks created during the ReDS install process. You may have more than one ReDS system configured allowing you to target multiple Amazon RDS instances. |
| region | Which AWS region the Amazon RDS instance and ReDS CloudFormation stacks exist. |
| instance_sizes | The predetermined instance sizes to use during scale up/down operations. Indexed from 0 |
| scale_down.cron | CRON syntax definition, in UTC for end time to remove scheduled_index minimum sized instance – when enabled *See schedule_enabled, scheduled_index |
| scale_down.alarm_duration, scale_down.threshold, scale_down.cooldown | Properties to control when the system is allowed to scale down one instance size due to CPUUtilization value. The default listed is after 5 minutes of Amazon RDS CPUUtilization < 10%, allowing one downsize per 60 minutes |
| scale_up.cron | CRON syntax definition, in UTC for start time to jump up to scheduled_index size instance – when enabled *See schedule_enabled, scheduled_index |
| scale_up.alarm_duration, scale_up.threshold, scale_up.cooldown | Properties to control when the system is allowed to scale up one instance size due to CPUUtilization value. The default listed is after 10 minutes of Amazon RDS CPUUtilization > 80%, allowing one upsize per 10 minutes |
| credits.alarm_duration, credits.threshold, credits.cooldown | Properties to control when the system is allowed to scale up one instance size due to CreditBalance value. The default listed is after 10 minutes of Amazon RDS CreditBalance < 2, allowing one upsize per 10 minutes |
| enabled | Whether the ReDS system is enabled |
| scheduled_index | Which index of instance_sizes to jump to during a scheduled increase |
| schedule_enabled | Whether or not the scheduled cron times are processed and enforced |
| Amazon RDS_identifer | The identifier of the Amazon RDS instance for the ReDS system to target |
Best practices
ReDS was designed to use AWS and programming best practices, including IAM roles granting least privilege to the executing code and integrated testing, to name just a few. We’d love to hear your feedback on the project or answer questions that you may have. Follow this link to the repository to check out the full README for settings and instructions.
The savings by using a ReDS setup are considerable. As a comparison, I pulled up the AWS Calculator and calculated the average monthly costs for a Multi-AZ, 20 GB SSD on-demand Amazon RDS instance in the us-west-2 (Oregon) region:
Standard Setup (without ReDS) – High Performance required 24/7:
M4.large – 100% monthly use: $261
ReDS Setup – High Performance during peak hours, with evenings lower + weekends lowest:
M4.large – 24% monthly use (M-F 9-5): $67
T2.medium – 50% monthly use (M-F off hours): $55
T2.small – 26% monthly use (Sat/Sun all day): $18
The total difference in savings is around $122 per month (or 47% of the total). In addition to the cost savings, if you worry that you ever may max out the m4.large, you can also put a larger instance next in line as insurance.
ReDS is now being installed for all new Managed Cloud customers and it is just one of the many ways we’re leveraging cutting-edge technology to keep our customers’ sites and apps online at an affordable cost. Our default installation approach is to allow upsizing of Amazon RDS instance sizes during a CPUUtilization high alarm, with scheduling disabled. This will add the “insurance policy” approach which can help increase system uptime during an unforeseen traffic spikes, while not introducing unforeseen instance size changes due to scheduled increases and decreases.
Stay tuned for our next AWS Lambda project, where we will build off this idea for a different service and describe how to use AWS to further increase resilience and cost savings.
Happy Coding!
Appendix 1: Example PHP MySQL Check and Retry
<?php
class DB {
function __construct() { $this->mysqli = $this->connect_mysqli(); }
function connect_mysqli() {
// connection code (not shown) http://php.net/manual/en/mysqli.construct.php
return $conn;
}
function system_query($query) {
if ( !property_exists($this,’timeout’) ) { $this->timeout = 1; }
if ( $this->mysqli->ping() ) {
unset($this->timeout);
return $this->mysqli->query($query);
} elseif ( $this->timeout < 30 ) {
sleep($this->timeout);
$this->timeout = ceil($this->timeout * 1.5);
return $this->system_query($query);
} else { throw new Exception(‘MySQL Backoff Limit Reached.’); }
}
}
¹ WordPress offers a plugin, named HyperDB, that claims to provide read/write splitting capability as well as other high performance database behaviors. However, the plugin is not widely used and its effectiveness and compatibility with the wide variety of plugins is unknown.
² This process of “read/write” query splitting is also known by its pattern name: Command Query Responsibility Segregation (CQRS). See Martin Fowler’s blog post on the subject for an in-depth look at how to accomplish this, and how hard it is to do properly.



